


Giới thiệu
Trong các bài trước, chúng ta đã đề cập đến hầu hết các nội dung liên quan đến Head (in-memory) block. Trong bài này, chúng ta sẽ đi sâu hơn vào các persistent blocks nằm trên disk.
Persistent block là gì và được tạo ra khi nào?
Một khối trên disk là tập hợp các chunks trong một khoảng thời gian cố định, bao gồm index riêng. Nó là một thư mục chứa nhiều file bên trong. Mỗi khối có một ID duy nhất, gọi là Universally Unique Lexicographically Sortable Identifier (ULID) .
Một khối có một đặc tính thú vị là các samples trong đó không thể thay đổi. Nếu bạn muốn thêm, xóa hoặc cập nhật samples, bạn phải viết lại toàn bộ khối với các sửa đổi cần thiết và khối mới sẽ có một ID mới. Không có mối quan hệ nào giữa hai khối này. Chúng ta có các lệnh xóa trên khối thông qua tombstone mà không cần động đến samples, vì việc viết lại một khối cho mỗi yêu cầu xóa nghe có vẻ không hợp lý; chúng ta sẽ thảo luận thêm về vấn đề này trong bài này.
Chúng ta đã thấy trong Phần 1 rằng khi Head block chứa đầy dữ liệu chunkRange*3/2 theo thời gian, chúng ta sẽ lấy dữ liệu chunkRange đầu tiên và chuyển đổi thành persistent block.

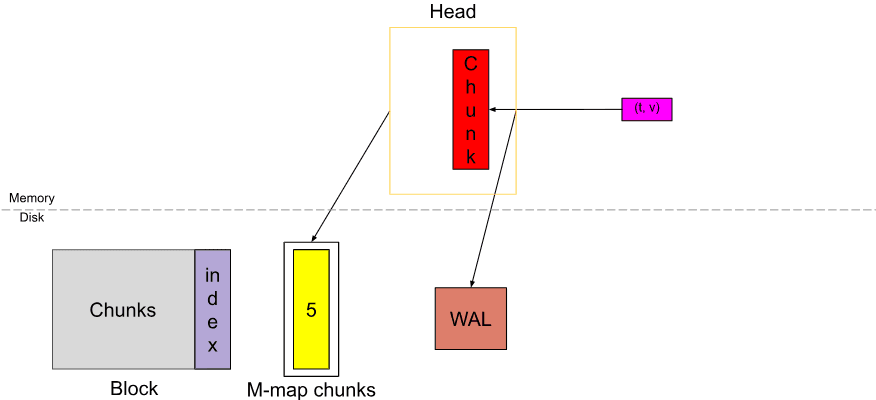
Ở đây chúng tôi gọi chunkRange như blockRange trong bối cảnh của các khối và khối đầu tiên được cắt từ Head trải dài 2h theo mặc định trong Prometheus.
Nhìn vào bức tranh tổng thể của TSDB bên dưới

Khi các khối trở nên cũ, nhiều khối sẽ được nén (hoặc hợp nhất) để tạo thành một khối mới lớn hơn, trong khi các khối cũ sẽ bị xóa. Vì vậy, chúng ta có 2 cách để tạo khối: từ khối Head và từ các khối hiện có. Chúng ta sẽ tìm hiểu về nén trong các bài viết sau.
Nội dung của một block
Một block gồm có 4 phần
meta.json: siêu dữ liệu của block.chunks: chứa các raw chunks mà không có bất kỳ siêu dữ liệu nào về chunks đó.index: chỉ mục của block này.tombstones: các dấu xóa để loại trừ các samples khi truy vấn block.
Ví dụ về block ID 01EM6Q6A1YPX4G9TEB20J22B2R, đây là cách các file sắp xếp trên disk
data
├── 01EM6Q6A1YPX4G9TEB20J22B2R
| ├── chunks
| | ├── 000001
| | └── 000002
| ├── index
| ├── meta.json
| └── tombstones
├── chunks_head
| ├── 000001
| └── 000002
└── wal
├── checkpoint.000003
| ├── 000000
| └── 000001
├── 000004
└── 000005Chúng ta hãy cùng tìm hiểu sâu hơn về từng vấn đề.
1. meta.json
Phần này chứa tất cả siêu dữ liệu cần thiết cho toàn bộ khối. Dưới đây là một ví dụ:
{
"ulid": "01EM6Q6A1YPX4G9TEB20J22B2R",
"minTime": 1602237600000,
"maxTime": 1602244800000,
"stats": {
"numSamples": 553673232,
"numSeries": 1346066,
"numChunks": 4440437
},
"compaction": {
"level": 1,
"sources": [
"01EM65SHSX4VARXBBHBF0M0FDS",
"01EM6GAJSYWSQQRDY782EA5ZPN"
]
},
"version": 1
}versioncho chúng ta biết cách phân tích file meta.- Mặc dù tên thư mục được đặt thành ULID, nhưng chỉ có một giá trị trong
ulidlà ID hợp lệ, tên thư mục có thể là bất kỳ tên nào. minTimevàmaxTimelà dấu thời gian tối thiểu và tối đa tuyệt đối giữa tất cả chunks có trong khối.statscho biết số lượng series, samples và chunks có trong khối.compactioncho biết lịch sử của khối.levelcho biết khối này đã trải qua bao nhiêu thế hệ.sourcescho biết khối này được tạo từ những khối nào (tức là khối được hợp nhất để tạo thành khối này).- Nếu nó được tạo từ Head block, thì
sourcesđược đặt thành chính nó (01EM6Q6A1YPX4G9TEB20J22B2Rtrong trường hợp này).
2. chunks
Thư mục chunks chứa một chuỗi các tệp được đánh số tương tự như WAL/checkpoint/head chunks. Mỗi file có dung lượng tối đa là 512MB. Đây là định dạng của một tệp riêng lẻ trong thư mục này:
┌──────────────────────────────┐
│ magic(0x85BD40DD) <4 byte> │
├──────────────────────────────┤
│ version(1) <1 byte> │
├──────────────────────────────┤
│ padding(0) <3 byte> │
├──────────────────────────────┤
│ ┌──────────────────────────┐ │
│ │ Chunk 1 │ │
│ ├──────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────┤ │
│ │ Chunk N │ │
│ └──────────────────────────┘ │
└──────────────────────────────┘Nó trông rất giống với memory-mapped head chunks file. Số magic xác định tệp này là tệp chunks. version cho chúng ta biết cách phân tích cú pháp tệp này. padding dành cho bất kỳ tiêu đề nào trong tương lai. Sau đó là danh sách chunks.
Sau đây là định dạng của một chunk riêng lẻ:
┌───────────────┬───────────────────┬──────────────┬────────────────┐
│ len <uvarint> │ encoding <1 byte> │ data <bytes> │ CRC32 <4 byte> │
└───────────────┴───────────────────┴──────────────┴────────────────┘Nó lại trông giống với memory-mapped head chunks trên disk, ngoại trừ việc thiếu series ref, mint và maxt. Chúng tôi cần thông tin bổ sung này cho Head chunks để tạo lại in-memory index khi khởi động. Nhưng trong trường hợp blocks, chúng tôi có thông tin bổ sung này trong index, vì index là nơi cuối cùng nó thuộc về, do đó chúng tôi không cần nó ở đây.
Để truy cập chunks này, chúng ta lại cần tham chiếu chunk đã nói trong Phần 3. Lặp lại những gì tôi đã nói: Tham chiếu dài 8 byte. 4 byte đầu tiên cho biết số tệp mà chunk tồn tại, và 4 byte cuối cùng cho biết vị trí offset trong tệp nơi chunk bắt đầu (tức là byte đầu tiên của len).
Nếu chunk nằm trong tệp 00093 và len của chunk bắt đầu tại vị trí byte 1234 trong tệp, thì tham chiếu của chunk đó sẽ là (92 << 32) | 1234 (các bit dịch trái rồi đến phép OR bitwise). Trong khi tên tệp sử dụng index dựa trên 1, thì tham chiếu chunks sử dụng chỉ mục dựa trên 0. Do đó, 00093 đã được chuyển đổi thành 92 khi tính toán tham chiếu chunk.
Đây là liên kết đến các tài liệu gốc về chunks format.
3. index
Index chứa tất cả những gì bạn cần để truy vấn dữ liệu của block. Nó không chia sẻ bất kỳ dữ liệu nào với block khác hoặc thực thể bên ngoài, giúp bạn có thể đọc/truy vấn khối mà không cần bất kỳ sự phụ thuộc nào.
Index là một “inverted index” cũng được sử dụng rộng rãi trong việc lập chỉ mục tài liệu. Fabian đã nói nhiều hơn về inverted index trong bài đăng trên blog của anh ấy, do đó tôi sẽ bỏ qua chủ đề đó ở đây vì bài viết này đã quá dài rồi.
Sau đây là góc nhìn tổng quan về index mà chúng ta sẽ tìm hiểu sâu hơn ngay sau đây.
┌────────────────────────────┬─────────────────────┐
│ magic(0xBAAAD700) <4b> │ version(1) <1 byte> │
├────────────────────────────┴─────────────────────┤
│ ┌──────────────────────────────────────────────┐ │
│ │ Symbol Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Series │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Index N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Label Offset Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Postings Offset Table │ │
│ ├──────────────────────────────────────────────┤ │
│ │ TOC │ │
│ └──────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────┘Giống như các tệp khác, số magic xác định tệp này là index file. version cho chúng ta biết cách phân tích cú pháp tệp này. Điểm vào của index là TOC, viết tắt của Table Of Contents (Mục lục). Vì vậy, trước tiên chúng ta sẽ bắt đầu TOC và tìm hiểu về các phần khác của index.
TOC
┌─────────────────────────────────────────┐
│ ref(symbols) <8b> │ -> Symbol Table
├─────────────────────────────────────────┤
│ ref(series) <8b> │ -> Series
├─────────────────────────────────────────┤
│ ref(label indices start) <8b> │ -> Label Index 1
├─────────────────────────────────────────┤
│ ref(label offset table) <8b> │ -> Label Offset Table
├─────────────────────────────────────────┤
│ ref(postings start) <8b> │ -> Postings 1
├─────────────────────────────────────────┤
│ ref(postings offset table) <8b> │ -> Postings Offset Table
├─────────────────────────────────────────┤
│ CRC32 <4b> │
└─────────────────────────────────────────┘Nó cho chúng ta biết chính xác vị trí (byte offset trong file) mà các thành phần riêng lẻ của index bắt đầu. Tôi đã đánh dấu vị trí mà mỗi tham chiếu trỏ đến trong định dạng index ở trên. Điểm bắt đầu của thành phần tiếp theo cũng cho chúng ta biết vị trí các thành phần riêng lẻ kết thúc. Nếu bất kỳ tham chiếu nào là 0, thì điều đó có nghĩa là phần tương ứng không tồn tại trong index, và do đó nên bỏ qua khi đọc.
Vì kích thước TOC cố định nên 52 byte cuối cùng của tệp có thể được coi là TOC.
Như bạn sẽ thấy trong các phần tiếp theo, mỗi thành phần sẽ có checksum riêng, ví dụ CRC32 để kiểm tra tính toàn vẹn của dữ liệu cơ bản.
Symbol Table
Phần này chứa danh sách đã được sắp xếp các chuỗi đã loại bỏ trùng lặp, được tìm thấy trong các cặp labels của tất cả series trong block này. Ví dụ: nếu chuỗi là {a="y", x="b"}, thì các ký hiệu sẽ là "a", "b", "x", "y".
┌────────────────────┬─────────────────────┐
│ len <4b> │ #symbols <4b> │
├────────────────────┴─────────────────────┤
│ ┌──────────────────────┬───────────────┐ │
│ │ len(str_1) <uvarint> │ str_1 <bytes> │ │
│ ├──────────────────────┴───────────────┤ │
│ │ . . . │ │
│ ├──────────────────────┬───────────────┤ │
│ │ len(str_n) <uvarint> │ str_n <bytes> │ │
│ └──────────────────────┴───────────────┘ │
├──────────────────────────────────────────┤
│ CRC32 <4b> │
└──────────────────────────────────────────┘len <4b> là số byte trong phần này và #symbolslà số ký hiệu. Theo sau là #symbolssố chuỗi được mã hóa utf-8, trong đó mỗi chuỗi có tiền tố độ dài, tiếp theo là số byte thô của chuỗi. Checksum (CRC32) để đảm bảo tính toàn vẹn.
Các phần khác trong index có thể tham chiếu đến bảng ký hiệu này cho bất kỳ chuỗi nào và do đó giảm đáng kể kích thước index. Byte offset mà ký hiệu bắt đầu trong tệp (tức là điểm bắt đầu của len(str_i)) tạo thành tham chiếu cho ký hiệu tương ứng, có thể được sử dụng ở những nơi khác thay vì chuỗi thực tế. Khi bạn cần chuỗi thực tế, bạn có thể sử dụng độ lệch để lấy nó từ bảng này.
Series
Phần này chứa danh sách tất cả thông tin về chuỗi có trong các khối này. Các chuỗi được sắp xếp theo thứ tự từ điển theo bộ nhãn của chúng.
┌───────────────────────────────────────┐
│ ┌───────────────────────────────────┐ │
│ │ series_1 │ │
│ ├───────────────────────────────────┤ │
│ │ . . . │ │
│ ├───────────────────────────────────┤ │
│ │ series_n │ │
│ └───────────────────────────────────┘ │
└───────────────────────────────────────┘Mỗi mục series được căn chỉnh 16 byte, nghĩa là độ lệch byte mà series bắt đầu chia hết cho 16. Do đó, chúng tôi đặt ID của series là offset/16 vị trí offset trỏ đến điểm bắt đầu của mục series. ID này được sử dụng để tham chiếu series này và bất cứ khi nào bạn muốn truy cập series, bạn có thể lấy vị trí trong chỉ mục bằng cách thực hiện lệnh ID*16.
Vì các series được sắp xếp theo thứ tự từ điển theo bộ labels của chúng nên danh sách các ID chuỗi được sắp xếp ngụ ý danh sách các series label được sắp xếp.
Ở đây, có một phần gây nhầm lẫn cho nhiều người trong index: posting là gì? series ID ở trên là một posting. Vì vậy, bất cứ khi nào chúng ta nói về posting trong ngữ cảnh của Prometheus TSDB, nó đề cập đến series ID. Nhưng tại sao lại là posting? Đây là phỏng đoán tốt nhất của tôi: trong thế giới index các tài liệu và các từ của nó với một inverted index, ID tài liệu thường được gọi là “posting” trong index. Ở đây, bạn có thể coi series là một tài liệu và một cặp label-value của một series là các từ trong tài liệu. Series ID -> ID tài liệu, ID tài liệu -> posting, Series ID -> posting.
Mỗi mục chứa bộ label của series và tham chiếu đến tất cả các chunks thuộc series này (tham chiếu là tham chiếu từ thư mục chunks).
┌──────────────────────────────────────────────────────┐
│ len <uvarint> │
├──────────────────────────────────────────────────────┤
│ ┌──────────────────────────────────────────────────┐ │
│ │ labels count <uvarint64> │ │
│ ├──────────────────────────────────────────────────┤ │
│ │ ┌────────────────────────────────────────────┐ │ │
│ │ │ ref(l_i.name) <uvarint32> │ │ │
│ │ ├────────────────────────────────────────────┤ │ │
│ │ │ ref(l_i.value) <uvarint32> │ │ │
│ │ └────────────────────────────────────────────┘ │ │
│ │ ... │ │
│ ├──────────────────────────────────────────────────┤ │
│ │ chunks count <uvarint64> │ │
│ ├──────────────────────────────────────────────────┤ │
│ │ ┌────────────────────────────────────────────┐ │ │
│ │ │ c_0.mint <varint64> │ │ │
│ │ ├────────────────────────────────────────────┤ │ │
│ │ │ c_0.maxt - c_0.mint <uvarint64> │ │ │
│ │ ├────────────────────────────────────────────┤ │ │
│ │ │ ref(c_0.data) <uvarint64> │ │ │
│ │ └────────────────────────────────────────────┘ │ │
│ │ ┌────────────────────────────────────────────┐ │ │
│ │ │ c_i.mint - c_i-1.maxt <uvarint64> │ │ │
│ │ ├────────────────────────────────────────────┤ │ │
│ │ │ c_i.maxt - c_i.mint <uvarint64> │ │ │
│ │ ├────────────────────────────────────────────┤ │ │
│ │ │ ref(c_i.data) - ref(c_i-1.data) <varint64> │ │ │
│ │ └────────────────────────────────────────────┘ │ │
│ │ ... │ │
│ └──────────────────────────────────────────────────┘ │
├──────────────────────────────────────────────────────┤
│ CRC32 <4b> │
└──────────────────────────────────────────────────────┘Phần bắt đầu len và kết thúc CRC32 giống như trước. Mục series bắt đầu bằng số cặp label-value có trong series, như labels count, theo sau là các cặp label-value được sắp xếp theo thứ tự từ điển (ví dụ: tên label). Thay vì lưu trữ chính chuỗi, chúng tôi sử dụng tham chiếu ký hiệu từ bảng ký hiệu ở đây. Nếu chuỗi là {a="y", x="b"}, thì mục series sẽ bao gồm tham chiếu ký hiệu theo "a", "y", "x", "b"cùng thứ tự.
Tiếp theo là số lượng chunks (chunks count) thuộc về series này trong thư mục chunks. Tiếp theo là một chuỗi siêu dữ liệu về indexed chunks, bao gồm thời gian tối thiểu (dấu thời gian của mẫu đầu tiên) và thời gian tối đa (dấu thời gian của mẫu cuối cùng) của chunk và tham chiếu của nó trong thư mục chunks. Chúng được sắp xếp theo thứ tự mint của chunks. Nếu bạn để ý định dạng trên, thực ra chúng ta đang lưu trữ mint và maxt bằng cách lấy giá trị khác nhau với dấu thời gian trước đó (giá trị ban đầu của cùng một chunk hoặc giá trị tối đa của chunk trước đó). Điều này làm giảm kích thước của siêu dữ liệu chunk vì chúng chiếm một phần lớn trong chỉ mục theo kích thước.
Việc giữ dấu mint và maxt trong index cho phép các truy vấn bỏ qua chunks không cần thiết trong phạm vi thời gian được truy vấn. Điều này khác với m-mapped Head chunks, trong đó mint và maxt nằm cùng với chunks để khôi phục chúng trong in-memory index của Head khi khởi động.
Label Offset Table và Label Index i
Cả hai đều được kết hợp, vì vậy chúng ta sẽ thảo luận cả hai cùng nhau. Label Index i đề cập đến bất kỳ mục nào Label Index 1 ... Label Index N trong index; chúng ta sẽ nói về một mục duy nhất Label Index i.
Hai phần này hiện không còn được sử dụng nữa; chúng được viết để tương thích ngược nhưng không được đọc trong phiên bản Prometheus mới nhất. Tuy nhiên, việc hiểu rõ cách sử dụng các phần này rất hữu ích và chúng ta sẽ xem chúng được thay thế bằng phần nào trong phần tiếp theo.
Mục đích của các phần này là lập chỉ mục các giá trị khả dĩ cho một tên label. Ví dụ: nếu chúng ta có hai chuỗi {a="b1", x="y1"} và {a="b2", x="y2"}, phần này cho phép chúng ta xác định các giá trị khả dĩ cho tên label a là [b1, b2]và cho x chúng là [y1, y2]. Định dạng này cũng cho phép lập chỉ mục một cái gì đó tương tự như tên label (a, x)có các giá trị khả dĩ [(b1, y1), (b2, y2)], nhưng chúng ta không sử dụng điều này trong Prometheus.
Label Index i
Đây là định dạng của một Label Index i duy nhất, vì vậy chúng ta có nhiều mục nhập như vậy theo thứ tự không theo thứ tự cụ thể. Đây là định dạng của một mục nhập duy nhất Label Index i:
┌───────────────┬────────────────┬────────────────┐
│ len <4b> │ #names <4b> │ #entries <4b> │
├───────────────┴────────────────┴────────────────┤
│ ┌─────────────────────────────────────────────┐ │
│ │ ref(value_0) <4b> │ │
│ ├─────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├─────────────────────────────────────────────┤ │
│ │ ref(value_n) <4b> │ │
│ └─────────────────────────────────────────────┘ │
│ . . . │
├─────────────────────────────────────────────────┤
│ CRC32 <4b> │
└─────────────────────────────────────────────────┘Từ các ví dụ trên, điều này giúp chúng ta lưu trữ danh sách [b1, b2], [y1, y2], [(b1, y1), (b2, y2)], trong khi mỗi danh sách có mục riêng trong chỉ mục len và CRC32 giống như trước.
#names là số lượng tên label mà các giá trị dành cho. Ví dụ, nếu chúng ta lập chỉ mục cho a hoặc x, #names sẽ là 1. Nếu chúng ta index cho (a, x), tức là 2 tên label, thì #names sẽ là 2.
#entries là số giá trị có thể có cho các tên label. Nếu các tên là a hoặc x hoặc chẵn (a, x), #entries thì bằng 2 vì mỗi tên có 2 giá trị có thể có.
Tiếp theo là #names * #entries số lượng tham chiếu đến các ký hiệu giá trị.
Ví dụ cho [b1, b2]
┌────┬───┬───┬─────────┬─────────┬───────┐
│ 16 │ 1 │ 2 │ ref(b1) | ref(b2) | CRC32 |
└────┴───┴───┴─────────┴─────────┴───────┘Ví dụ cho [(b1, y1), (b2, y2)]
┌────┬───┬───┬─────────┬─────────┬─────────┬─────────┬───────┐
│ 24 │ 2 │ 2 │ ref(b1) | ref(y1) │ ref(b2) | ref(y2) | CRC32 |
└────┴───┴───┴─────────┴─────────┴─────────┴─────────┴───────┘Label Offset Table
Trong khi Label Index i lưu trữ danh sách các giá trị có thể, Label Offset Table tập hợp các tên label và hoàn thiện label name-value index.
Đây là định dạng của Label Offset Table
┌─────────────────────┬──────────────────────┐
│ len <4b> │ #entries <4b> │
├─────────────────────┴──────────────────────┤
│ ┌────────────────────────────────────────┐ │
│ │ n = 1 <1b> │ │
│ ├──────────────────────┬─────────────────┤ │
│ │ len(name) <uvarint> │ name <bytes> │ │
│ ├──────────────────────┴─────────────────┤ │
│ │ offset <uvarint64> │ │
│ └────────────────────────────────────────┘ │
│ . . . │
├────────────────────────────────────────────┤
│ CRC32 <4b> │
└────────────────────────────────────────────┘Trình tự này lưu trữ các mục nhập để trỏ tên label đến các giá trị có thể có của nó, ví dụ, điểm a ở phần Label Index i chứa [b1, b2].
Bảng trên có len và CRC32 giống như các phần khác, #entries là số lượng mục nhập trong bảng này. Tiếp theo là các mục nhập thực tế.
Mỗi mục bắt đầu bằng n số lượng tên label, theo sau là n số lượng tên label thực tế chứ không phải ký hiệu. Nếu bạn để ý, chuỗi này len(name) <uvarint> │ name <bytes> giống với cách chúng ta lưu trữ trong bảng ký hiệu. Trong Prometheus, chúng ta chỉ có n=1, nghĩa là chúng ta chỉ index các giá trị label khả dĩ cho một tên label duy nhất, chứ không phải cho các bộ như (a, x), vì số lượng các kết hợp như vậy sẽ rất lớn và không thực tế để lưu trữ tất cả.
Vì chúng tôi index tên label đơn nên chúng tôi có thể lưu trữ chuỗi trực tiếp vì số lượng tên label thường nhỏ và do đó ngăn chặn việc tải trang đĩa từ bảng ký hiệu để tra cứu tên label.
Mục nhập kết thúc bằng một offset trong tệp, trỏ đến phần đầu của phần liên quan Label Index i. Ví dụ: đối với tên label a, offset sẽ trỏ đến phần Label Index i lưu trữ [b1, b2]. Tên label x sẽ trỏ đến Label Index i phần lưu trữ [y1, y2].
Vì chúng ta chỉ index các tên label riêng lẻ, chúng ta cũng không lưu trữ Label Index i thành các bộ dữ liệu (a, x) như chúng ta đã thấy ở ví dụ trên cho thấy điều này là khả thi. Trước đây, người ta từng cân nhắc việc có giá trị label tổng hợp như vậy, nhưng đã bị loại bỏ vì không có nhiều trường hợp sử dụng.
Postings Offset Table và Postings i
Hai mục này được liên kết theo cách tương tự như trên, nơi Postings i lưu trữ danh sách các bài đăng và Postings Offset Table tham chiếu đến các mục đó theo độ lệch. Nếu bạn còn nhớ, một posting là một series ID, trong ngữ cảnh của index này là độ lệch mà series bắt đầu trong tệp chia cho 16 vì nó được căn chỉnh 16 byte.
Postings i
Một Postings i đại diện cho “danh sách postings”, về cơ bản là một danh sách postings đã được sắp xếp. Hãy cùng xem định dạng của một danh sách riêng lẻ như vậy và chúng ta sẽ làm việc với một ví dụ.
┌────────────────────┬────────────────────┐
│ len <4b> │ #entries <4b> │
├────────────────────┴────────────────────┤
│ ┌─────────────────────────────────────┐ │
│ │ ref(series_1) <4b> │ │
│ ├─────────────────────────────────────┤ │
│ │ ... │ │
│ ├─────────────────────────────────────┤ │
│ │ ref(series_n) <4b> │ │
│ └─────────────────────────────────────┘ │
├─────────────────────────────────────────┤
│ CRC32 <4b> │
└─────────────────────────────────────────┘Định dạng này không thể đơn giản hơn được nữa. Nó có len và CRC32 như thường lệ. Tiếp theo #entries là số lượng bài đăng trong danh sách này, và sau đó là danh sách được sắp xếp theo #entries số lượng bài đăng (series ID, cũng là tham chiếu).
Bạn có thể đang thắc mắc chúng ta lưu trữ những bài đăng nào trong danh sách này. Hãy lấy ví dụ về hai chuỗi này: {a="b", x="y1"} với series ID 120, {a="b", x="y2"} với ID chuỗi 145. Tương tự như cách chúng ta đã xem xét các giá trị label khả dĩ cho tên label ở trên, ở đây chúng ta xem xét các series khả dĩ cho một cặp label-value. Từ ví dụ trên, a="b"có mặt trong cả hai chuỗi, vì vậy chúng ta phải lưu trữ một danh sách [120, 145]. Đối với x="y1"và x="y2", chúng chỉ xuất hiện trong một series, vì vậy chúng ta phải lưu trữ [120]và [145] cho chúng tương ứng.
Chúng tôi chỉ lưu trữ danh sách cho các cặp label mà chúng tôi thấy trong series. Vì vậy, trong ví dụ trên, chúng tôi không lưu trữ danh sách bài đăng cho các cặp label như a="y1"hoặc x="b", vì chúng không bao giờ xuất hiện trong bất kỳ series nào.
Postings Offset Table
Giống như cách Label Offset Table trỏ tên label tới các giá trị có thể có trong Label Index i, tương tự như Postings Offset Tablecách trỏ cặp label tới các bài đăng có thể có trong Postings i.
┌─────────────────────┬──────────────────────┐
│ len <4b> │ #entries <4b> │
├─────────────────────┴──────────────────────┤
│ ┌────────────────────────────────────────┐ │
│ │ n = 2 <1b> │ │
│ ├──────────────────────┬─────────────────┤ │
│ │ len(name) <uvarint> │ name <bytes> │ │
│ ├──────────────────────┼─────────────────┤ │
│ │ len(value) <uvarint> │ value <bytes> │ │
│ ├──────────────────────┴─────────────────┤ │
│ │ offset <uvarint64> │ │
│ └────────────────────────────────────────┘ │
│ . . . │
├────────────────────────────────────────────┤
│ CRC32 <4b> │
└────────────────────────────────────────────┘Điều này trông rất giống với Label Offset Table, nhưng có thêm giá trị label. len và CRC32 hoạt động như bình thường.
#entries là số lượng mục nhập trong bảng này. nLuôn luôn là 2, cho biết số lượng phần tử chuỗi theo sau (tức là tên label và giá trị label). Vì chúng ta có n ở đây, bảng có thể index các cặp label tổng hợp như (a="b", x="y1"), nhưng chúng ta không làm vậy vì các trường hợp sử dụng cho việc này rất hạn chế và không có sự đánh đổi tốt.
n tiếp theo là chuỗi thực tế cho tên label và giá trị label. Một lần nữa, các cặp nhãn riêng lẻ nhìn chung không nhiều, do đó chúng ta có thể lưu trữ chuỗi thô ở đây và tránh việc truy cập gián tiếp đến bảng ký hiệu vì bảng này sẽ được truy cập rất nhiều lần. Ưu điểm chính của bảng ký hiệu nằm ở các Series mà cùng một ký hiệu được lặp lại nhiều lần.
Một mục nhập duy nhất kết thúc bằng một offset đến đầu danh sách Postings i. Từ ví dụ trên, một mục nhập for name="a", value="b" sẽ trỏ đến danh sách postings [120, 145], mục nhập name="x", value="y1" sẽ trỏ đến danh sách postings [120].
Các mục được sắp xếp dựa trên tên label và giá trị, trước tiên là tên label, và đối với các cặp có cùng tên, việc sắp xếp sẽ được thực hiện theo giá trị. Điều này cho phép chúng ta chạy tìm kiếm nhị phân cho cặp nhãn cần thiết. Ngoài ra, để có được các giá trị khả dĩ cho một tên nhãn nhất định, chúng ta có thể tìm đến cặp nhãn đầu tiên khớp với tên nhãn và lặp lại từ đó để lấy tất cả các giá trị. Do đó, bảng này thay thế cho dấu ngoặc Label Offset Table kép và dấu ngoặc Label Index i kép. Đây là một lý do khác để lưu trữ các chuỗi thực tế tại đây để truy cập nhanh hơn vào các giá trị label.
Danh sách postings này và postings offset table tạo thành inverted index. Để index tài liệu bằng inverted index, với mỗi từ, chúng tôi lưu trữ một danh sách các tài liệu mà từ đó xuất hiện. Tương tự, với mỗi cặp label-value, chúng tôi lưu trữ danh sách các series mà từ đó xuất hiện.
Đây là phần kết thúc của phần lớn nội dung index. Đây là liên kết đến các tài liệu gốc về index format.
4. tombstones
Tombstone là các dấu hiệu xóa, tức là chúng cho chúng ta biết khoảng thời gian nào của series nào cần bỏ qua trong quá trình đọc. Đây là tệp duy nhất trong khối được tạo và sửa đổi sau khi ghi một khối để lưu trữ các yêu cầu xóa.
┌────────────────────────────┬─────────────────────┐
│ magic(0x0130BA30) <4b> │ version(1) <1 byte> │
├────────────────────────────┴─────────────────────┤
│ ┌──────────────────────────────────────────────┐ │
│ │ Tombstone 1 │ │
│ ├──────────────────────────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────────────────────────┤ │
│ │ Tombstone N │ │
│ ├──────────────────────────────────────────────┤ │
│ │ CRC<4b> │ │
│ └──────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────┘Số magic cho biết đây là tệp tombstones (đoán xem con số này là sinh nhật của ai? Gợi ý: một người bảo trì Prometheus đã triển khai tính năng xóa trong TSDB). Con số này versioncho biết cách phân tích cú pháp tệp. Tiếp theo là một chuỗi tombstones mà chúng ta sẽ xem xét ngay sau đây. Tệp kết thúc bằng một tổng kiểm tra ( CRC32) trên tất cả các tombstones.
┌────────────────────────┬─────────────────┬─────────────────┐
│ series ref <uvarint64> │ mint <varint64> │ maxt <varint64> │
└────────────────────────┴─────────────────┴─────────────────┘Trường đầu tiên là tham chiếu series (hay còn gọi là series ID, hay còn gọi là posting) mà tombstone này thuộc về. Trường mint xuyên suốt maxt là khoảng thời gian mà việc xóa tham chiếu đến, do đó chúng ta nên bỏ qua khoảng thời gian đó cho series được đề cập bởi series ref trong khi đọc các chunks. Khi một series duy nhất có nhiều khoảng thời gian bị xóa không chồng chéo, chúng sẽ tạo ra nhiều hơn 1 tombtone.
Đây là liên kết đến các tài liệu gốc về tombstones format.
Kết luận
Trong trường hợp Head block, chúng ta có inverted index trong bộ nhớ cùng với tên label thành các giá trị có thể được ánh xạ hiệu quả trong bộ nhớ.
Trong bài viết này, chúng ta đã thấy khối trông như thế nào trên đĩa. Đặc biệt là phần index chi tiết, chiếm phần lớn nội dung bài viết. Bạn có thể có nhiều câu hỏi, chẳng hạn như mục đích sử dụng của các phần đó trong index là gì, chúng đóng vai trò gì trong một truy vấn, loại truy vấn nào thường được chạy trên một khối hoặc index, v.v.
Code tham khảo
tsdb/block.go có mã để đọc và ghi tệp meta. Nhìn chung, đây là trung tâm cho mọi thứ liên quan đến persistent block.
tsdb/chunks/chunks.go có mã để đọc và ghi các tập tin trong thư mục chunks.
tsdb/index/index.go có mã để đọc và ghi index file.
tsdb/tombstones/tombstones.go có mã để đọc và ghi tombstones file.
Tất cả các tệp này đều hướng đến việc triển khai từng thành phần riêng lẻ của khối. Chúng ta sẽ xem đoạn mã kết hợp tất cả những điều này trong quá trình đọc và ghi khối trong các bài đăng trên blog về truy vấn và nén.