


Giới thiệu
Trong phần trước, tôi đã đề cập rằng khi một chunk “đầy”, nó sẽ được flush xuống disk và memory mapped. Điều này giúp giảm thiểu dung lượng bộ nhớ của Head block và cũng giúp tăng tốc độ phát lại WAL. Chúng ta sẽ tìm hiểu sâu hơn về cách thiết kế tính năng này trong Prometheus trong bài viết này.
Ghi các chunks
Khi một chunk đầy, chúng ta cắt một chunk mới và các chunk cũ hơn sẽ trở nên bất biến và chỉ có thể đọc được từ (khối màu vàng bên dưới).

Và thay vì lưu trữ nó trong bộ nhớ, nó flush vào disk và lưu trữ một tham chiếu để truy cập nó sau.
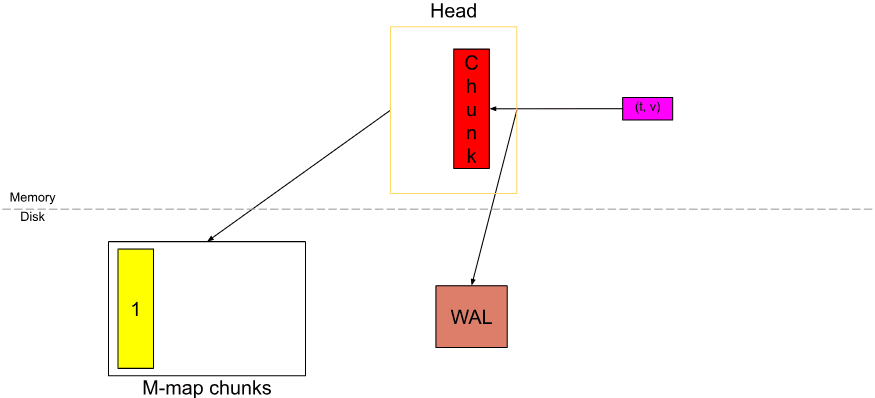
Chunk đã được flushed này là memory-mapped chunk từ disk. Tính bất biến là yếu tố quan trọng nhất ở đây, nếu không, việc viết lại các chunks đã nén sẽ quá kém hiệu quả cho mọi sample.
Format trên disk
File
Các chunks này nằm trong thư mục riêng gọi là chunks_head và có trình tự tệp tương tự như WAL (ngoại trừ việc nó bắt đầu bằng 1). Ví dụ:
data
├── chunks_head
| ├── 000001
| └── 000002
└── wal
├── checkpoint.000003
| ├── 000000
| └── 000001
├── 000004
└── 000005Kích thước tối đa của tệp được giữ ở mức 128MB. Giờ hãy đi sâu hơn vào một tệp duy nhất, tệp này chứa tiêu đề là 8MB.
┌──────────────────────────────┐
│ magic(0x0130BC91) <4 byte> │
├──────────────────────────────┤
│ version(1) <1 byte> │
├──────────────────────────────┤
│ padding(0) <3 byte> │
├──────────────────────────────┤
│ ┌──────────────────────────┐ │
│ │ Chunk 1 │ │
│ ├──────────────────────────┤ │
│ │ ... │ │
│ ├──────────────────────────┤ │
│ │ Chunk N │ │
│ └──────────────────────────┘ │
└──────────────────────────────┘Magic Number là bất kỳ số nào có thể xác định file duy nhất là memory-mapped head chunks. Chunk Format cho chúng ta biết cách giải mã chunks trong file. Phần đệm bổ sung là để cho phép bất kỳ tùy chọn tiêu đề nào trong tương lai mà chúng ta có thể cần.
Sau phần file header, phần tiếp theo là các chunks.
Chunks
Một chunk trông như thế này
┌─────────────────────┬───────────────────────┬───────────────────────┬───────────────────┬───────────────┬──────────────┬────────────────┐
| series ref <8 byte> | mint <8 byte, uint64> | maxt <8 byte, uint64> | encoding <1 byte> | len <uvarint> | data <bytes> │ CRC32 <4 byte> │
└─────────────────────┴───────────────────────┴───────────────────────┴───────────────────┴───────────────┴──────────────┴────────────────┘series ref này là tham chiếu series giống như chúng ta đã nói ở Phần 2, đó là series id được sử dụng để truy cập series trong bộ nhớ. mint và maxt là dấu thời gian tối thiểu và tối đa được thấy trong các samples của chunk. encoding là mã hóa được sử dụng để nén các chunks. len là số byte tiếp theo và datalà số byte thực tế của chunk đã nén.
CRC32 là checksum nội dung trên của chunk được sử dụng để kiểm tra tính toàn vẹn của dữ liệu.
Đọc các chunks
Đối với mỗi chunk, Head block lưu trữ mint và maxt của chunk đó cùng với tham chiếu trong bộ nhớ để truy cập khối đó.
Tham chiếu dài 8 byte. 4 byte đầu tiên cho biết số file mà chunk tồn tại, và 4 byte cuối cùng cho biết vị trí bắt đầu của chunk trong file (tức là byte đầu tiên của series ref). Nếu chunk nằm trong tệp 00093 và series ref bắt đầu tại vị trí bắt đầu của byte 1234 trong file, thì tham chiếu của chunk đó sẽ là (93 << 32) | 1234 (các bit dịch trái rồi đến phép toán OR bitwise).
Chúng tôi lưu trữ mint và maxt trong Head để có thể chọn chunk mà không cần nhìn vào đĩa. Khi cần truy cập chunk, chúng tôi chỉ truy cập mã hóa và dữ liệu chunk bằng tham chiếu.
Trong code, file trông giống như một lát cắt byte khác (mỗi lát cắt một tệp) và truy cập lát cắt tại một chỉ mục nào đó để lấy dữ liệu khối trong khi hệ điều hành ánh xạ lát cắt trong bộ nhớ vào ổ đĩa bên dưới. Ánh xạ bộ nhớ từ ổ đĩa là một tính năng của hệ điều hành, chỉ lấy phần đĩa đang được truy cập vào bộ nhớ chứ không phải toàn bộ tệp.
Replaying khi khởi động
Trong Phần 2, chúng ta đã nói về phát lại WAL, trong đó chúng ta phát lại từng sample riêng lẻ để tái tạo chunk nén. Giờ đây, khi đã có các chunks nén đầy đủ trên đĩa, chúng ta không cần phải tạo lại các chunks này trong khi vẫn cần tạo các chunks từ WAL chưa đầy. Với các memory-mapped chunks này từ đĩa, quá trình phát lại diễn ra như sau.
Khi khởi động, trước tiên chúng ta lặp lại tất cả các chunks trong thư mục chunks_head và xây dựng bản đồ series ref -> [list of chunk references along with mint and maxt belonging to this series ref] trong bộ nhớ.
Sau đó, chúng tôi tiếp tục phát lại WAL như mô tả trong Phần 2 nhưng có một vài sửa đổi:
- Khi chúng ta tìm thấy bản ghi
Seriessau khi tạo series, chúng ta sẽ tìm kiếm tham chiếu series trong bản đồ ở trên và nếu có bất kỳ memory-mapped chunks, chúng ta sẽ đính kèm danh sách đó vào seriesnày. - Khi chúng ta tìm thấy bản ghi
Samples, nếu series tương ứng của sample có bất kỳ memory-mapped chunks và nếu sample nằm trong khoảng thời gian mà nó bao phủ, thì chúng ta sẽ bỏ qua sample. Nếu không, chúng ta sẽ nhập sample đó vào Head block.
Những cải tiến mang lại
Sự phức tạp bổ sung này có ích gì khi chúng ta có thể lưu trữ các chunks trong bộ nhớ và WAL? Tính năng này mới được bổ sung gần đây vào năm 2020, vậy hãy cùng xem nó mang lại những gì. (Bạn có thể xem benchmark graphs trên blog Grafana Labs)
Tiết kiệm bộ nhớ
Nếu bạn phải lưu trữ chunk trong bộ nhớ, nó có thể chiếm từ 120 đến 200 byte (hoặc thậm chí nhiều hơn tùy thuộc vào khả năng nén của samples). Giờ đây, nó được thay thế bằng 24 byte – mỗi chunks có 8 byte tham chiếu, thời gian tối thiểu và thời gian tối đa của chunk.
Nghe có vẻ như bộ nhớ sẽ giảm 80-90%, nhưng thực tế lại khác. Head cần lưu trữ nhiều thứ hơn, chẳng hạn như in-memory index, tất cả các ký hiệu (giá trị label), v.v., và các phần khác của TSDB cần một lượng bộ nhớ nhất định.
Trong thực tế, chúng ta có thể thấy dung lượng bộ nhớ giảm 15-50% tùy thuộc vào tốc độ thu thập samples và tốc độ tạo series mới (gọi là “churn”). Một điều cần lưu ý nữa là nếu bạn đang chạy một số truy vấn liên quan đến chunks này trên đĩa, thì chúng cần được tải vào bộ nhớ để xử lý. Vì vậy, đây không phải là sự giảm tuyệt đối về mức sử dụng bộ nhớ tối đa.
Khởi động nhanh hơn
Phát lại WAL là phần chậm nhất của quá trình khởi động. Chủ yếu là giải mã các bản ghi WAL từ đĩa và xây dựng lại các đoạn chunks nén từ các samples riêng lẻ, là những phần chậm nhất trong quá trình phát lại. Việc lặp lại memory-mapped chunks tương đối nhanh.
Chúng ta không thể tránh việc giải mã các bản ghi vì cần kiểm tra tất cả các bản ghi. Như bạn đã thấy ở trên trong bản phát lại, chúng ta đang bỏ qua các samples nằm trong phạm vi memory-mapped chunks. Ở đây, chúng ta tránh việc tạo lại các chunks đã nén đầy đủ đó, do đó tiết kiệm được thời gian phát lại. Phương pháp này đã được chứng minh là giảm thời gian khởi động từ 15-30%.
Garbage collection
Quá trình thu gom rác trong bộ nhớ diễn ra trong quá trình cắt bớt Head, khi đó nó chỉ xóa tham chiếu của các chunks cũ hơn thời gian cắt bớt T. Tuy nhiên, các file vẫn còn trên đĩa. Tương tự như các phân đoạn WAL, chúng ta cũng cần xóa các tệp m-mapped cũ thường xuyên.
Với mỗi file memory-mapped chunk hiện diện (tức là cũng mở trong TSDB), chúng tôi lưu trữ trong bộ nhớ thời gian tối đa tuyệt đối giữa tất cả các chunks có trong file. Đối với file trực tiếp (tệp mà chúng tôi hiện đang ghi chunks), chúng tôi cập nhật thời gian tối đa này trong bộ nhớ khi chúng tôi thêm chunks mới. Trong quá trình khởi động lại, khi chúng tôi lặp lại tất cả các memory-mapped chunks, chúng tôi sẽ khôi phục thời gian tối đa của các file trong bộ nhớ đó.
Vì vậy, khi việc cắt bớt Head xảy ra đối với dữ liệu trước thời gian T, chúng ta gọi việc cắt bớt trên các tệp này theo thời gian T. Các tệp có thời gian tối đa dưới T(ngoại trừ tệp trực tiếp) sẽ bị xóa tại thời điểm này trong khi vẫn giữ nguyên trình tự (nếu các tệp nằm trong khoảng thời gian 5, 6, 7, 8và nếu các tệp nằm ngoài thời gian , 5thì chỉ có các tệp bị xóa và trình tự còn lại sẽ là ).7T56, 7, 8
Sau khi cắt bớt, chúng tôi đóng tệp trực tiếp và bắt đầu một tệp mới vì trong trường hợp dung lượng thấp và thiết lập nhỏ, có thể mất nhiều thời gian để đạt đến kích thước tối đa của tệp. Vì vậy, việc xoay vòng các tệp ở đây sẽ giúp xóa các chunks cũ trong lần cắt bớt tiếp theo.
Code tham khảo
tsdb/chunks/head_chunks.go có đầy đủ các chức năng thực hiện ghi chunks vào đĩa, truy cập vào đó bằng tham chiếu, cắt bớt, xử lý các tệp và cách lặp lại chunks.
tsdb/head.go sử dụng phần trên như black box để ánh xạ bộ nhớ các chunks của nó từ đĩa.