


Giới thiệu
Các Mô hình Ngôn ngữ Lớn (LLM) đã cách mạng hóa cách chúng ta tương tác với AI, nhưng chúng gặp phải một hạn chế nghiêm trọng: không có trạng thái. Không có khả năng lưu giữ thông tin từ các tương tác trước đó, LLM gặp khó khăn trong việc duy trì ngữ cảnh cho các cuộc trò chuyện kéo dài hoặc các tác vụ phức tạp nhiều bước. Chúng có xu hướng tạo ra ảo giác hoặc đưa ra phản hồi chung chung chỉ dựa trên dữ liệu đào tạo, thay vì tận dụng thông tin ngữ cảnh cụ thể từ các tương tác trước đó.
Thách thức này càng trở nên rõ rệt hơn khi xử lý các cửa sổ ngữ cảnh hạn chế. Mặc dù bạn có thể cung cấp ngữ cảnh mở rộng cho mỗi yêu cầu, nhưng cách tiếp cận này dẫn đến:
- Tiêu thụ và chi phí token cao
- Tăng độ trễ xử lý
- Giảm tính mạch lạc trong phản hồi
- Lỗ hổng bảo mật tiềm ẩn từ tình trạng tràn ngữ cảnh
Bộ nhớ dài hạn dựa trên vector
Một trong những phương pháp hiệu quả nhất để khắc phục những hạn chế này là triển khai Retrieval-Augmented Generation (RAG) với cơ sở dữ liệu vector thay vì chỉ dựa vào bộ nhớ làm việc cơ bản. Giải pháp này xử lý lịch sử hội thoại, kiến thức và thông tin nhiệm vụ như các vector có thể tìm kiếm, cho phép truy xuất ngữ nghĩa của ngữ cảnh liên quan mà không làm quá tải cửa sổ ngữ cảnh của LLM.
Cách tiếp cận thực tế
Trong hướng dẫn này, chúng ta sẽ xây dựng một hệ thống bộ nhớ dài hạn hoạt động bằng cách sử dụng:
- n8n : Nền tảng tự động hóa quy trình làm việc mạnh mẽ, không cần mã/mã thấp
- OpenAI : Dành cho LLM và các mô hình nhúng (bạn có thể thay thế bằng các nhà cung cấp khác)
- Qdrant : Cơ sở dữ liệu vector hiệu suất cao
- Cohere : Để xếp hạng lại kết quả (tùy chọn nhưng được khuyến nghị)
Tổng quan về kiến trúc
Giải pháp bao gồm hai thành phần chính:
- Hệ thống truy xuất bộ nhớ : Trước khi trả lời bất kỳ truy vấn nào, AI Agent sẽ tìm kiếm trong cơ sở dữ liệu vector để tìm bối cảnh lịch sử có liên quan
- Hệ thống lưu trữ bộ nhớ : Sau mỗi lần tương tác, cuộc trò chuyện và kết quả của nó được vector hóa và lưu trữ để tham khảo trong tương lai
Chúng ta hãy cùng tìm hiểu cách thực hiện nhé!
Hướng dẫn thực hiện
Bước 1: Thiết lập Qdrant
Đầu tiên, triển khai phiên bản Qdrant của bạn bằng Docker Compose:
services:
qdrant:
image: "qdrant/qdrant:latest"
environment:
- SERVICE_FQDN_QDRANT_6333
- "QDRANT_SERVICE_API_KEY=${SERVICE_PASSWORD}"
volumes:
- "qdrant-storage:/qdrant/storage"
ports:
- "6333:6333"
- "6334:6334"
expose:
- "6333"
- "6334"
healthcheck:
test:
- CMD-SHELL
- "bash -c ':> /dev/tcp/127.0.0.1/6333' || exit 1"
interval: 5s
timeout: 5s
retries: 3
volumes:
qdrant-storage:Sau đó, tạo một Collection có tên ltm:
- Kích thước vector : 1024 chiều
- Khoảng cách đo lường : Độ tương tự Cosine
- Mô hình nhúng :
text-embedding-3-smalltừ OpenAI
Bước 2: Xây dựng quy trình làm việc n8n
Quy trình làm việc bao gồm một số nút chính:
1. Node Chat Trigger
Thao tác này sẽ khởi tạo luồng hội thoại khi nhận được tin nhắn.
2. AI Agent với Công cụ RAG_MEMORY
Cốt lõi của hệ thống là một AI Agent được cấu hình để sử dụng truy xuất vector thay vì bộ nhớ làm việc truyền thống.
// RAG_MEMORY tool configuration
{
"mode": "retrieve-as-tool",
"toolName": "RAG_MEMORY",
"toolDescription": "Agent's long term memory as RAG",
"qdrantCollection": "ltm",
"topK": 20,
"useReranker": true
}3. Structured Output Parser
Định dạng phản hồi của Agent thành định dạng JSON có cấu trúc:
{
"sessionId": "unique-session-id",
"chatInput": "user's message",
"output": "agent's response"
}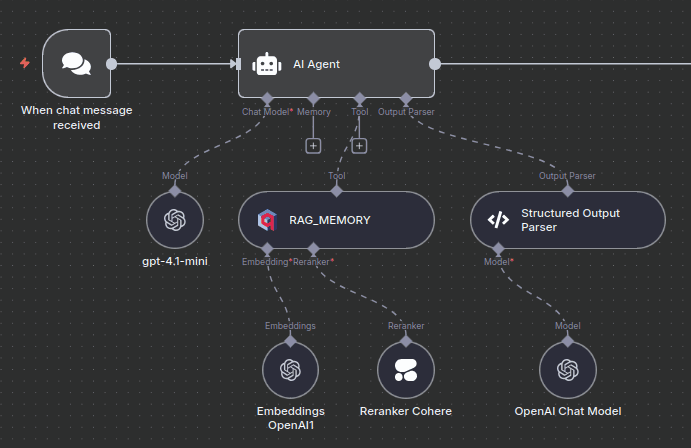
4. Node vector store
Sau mỗi lần tương tác, node này sẽ lưu trữ cuộc trò chuyện trong Qdrant bằng cách sử dụng:
- Bộ tách văn bản : Bộ tách ký tự đệ quy (kích thước khối: 200, chồng chéo: 40)
- Nhúng : Cùng một mô hình như truy xuất để đảm bảo tính nhất quán
5. Định dạng phản hồi
Nút cuối cùng để định dạng đầu ra cho giao diện trò chuyện.
Bước 3: Lời nhắc của Hệ thống AI Agent (Tùy chọn nhưng được khuyến nghị)
Để tối đa hóa hiệu quả của hệ thống trí nhớ dài hạn, hãy cấu hình AI Agent của bạn bằng lời nhắc chuyên biệt này:
# AI Agent with RAG_MEMORY System
You are an AI assistant that uses RAG_MEMORY retrieval instead of working memory to maintain context between interactions.
## Core Protocol
**Before every response:**
1. Query RAG_MEMORY for relevant context
2. Analyze retrieved information
3. Base your response on this context
## Key Principles
- **Never** store information in session memory
- **Always** retrieve context via RAG_MEMORY
- Be transparent about context retrieval
- Maintain consistency with retrieved information
## Query Strategy
- Use specific keywords related to the current topic
- Combine multiple searches when needed
- Prioritize relevance over quantity
## Special Cases
- **First interaction**: Search for any relevant user-provided terms
- **Topic changes**: Run new searches for the new topic
- **No results found**: Proceed normally and store new information
## Goal
Simulate persistent memory through intelligent retrieval, providing continuity across all interactions.Bước 4: Kiểm tra việc triển khai của bạn
- Cuộc trò chuyện ban đầu : Bắt đầu bằng phần giới thiệu đơn giản và một số thông tin thực tế
- Kiểm tra ngữ cảnh : Trong phiên mới, hãy hỏi về thông tin đã đề cập trước đó
- Truy vấn phức tạp : Kiểm tra lý luận nhiều bước đòi hỏi bối cảnh lịch sử
- Kiểm tra hiệu suất : Theo dõi việc sử dụng mã thông báo và thời gian phản hồi
Nó hoạt động như thế nào
Quá trình lưu trữ bộ nhớ
- Đầu vào của người dùng → AI xử lý truy vấn
- Phản hồi AI → Được tạo dựa trên ngữ cảnh đã truy xuất
- Vector hóa → Cuộc hội thoại được chia nhỏ và nhúng
- Lưu trữ → Các vector được lưu trữ trong Qdrant với siêu dữ liệu
Quá trình truy xuất bộ nhớ
- Truy vấn mới → Kích hoạt công cụ RAG_MEMORY
- Tìm kiếm ngữ nghĩa → Tìm bối cảnh lịch sử có liên quan
- Xếp hạng lại → Cohere ưu tiên các kết quả có liên quan nhất
- Tích hợp ngữ cảnh → AI sử dụng thông tin đã thu thập để phản hồi
Kết luận
Việc triển khai bộ nhớ dài hạn cho LLM sử dụng kho lưu trữ vector là một bước tiến đáng kể trong việc tạo ra các trợ lý AI thông minh hơn và nhận thức ngữ cảnh tốt hơn. Giải pháp dựa trên n8n này cung cấp một phương pháp thiết thực, sẵn sàng cho sản xuất, có thể triển khai nhanh chóng mà vẫn đủ linh hoạt để tùy chỉnh.
Sự kết hợp giữa tìm kiếm ngữ nghĩa, lưu trữ có cấu trúc và truy xuất thông minh tạo ra một hệ thống AI thực sự “ghi nhớ” – lý tưởng cho hỗ trợ khách hàng, trợ lý cá nhân, công cụ giáo dục và bất kỳ ứng dụng nào yêu cầu ngữ cảnh liên tục.
Khi công nghệ cơ sở dữ liệu vector và mô hình nhúng tiếp tục được cải thiện, các hệ thống này sẽ trở nên mạnh mẽ hơn nữa. Hãy bắt đầu thử nghiệm ngay hôm nay và mang đến cho AI của bạn món quà trí nhớ!