


Giới thiệu
Bạn muốn chạy các mô hình ngôn ngữ lớn (LLM) như DeepSeek-R1 hay Llama-3 ngay trên chiếc laptop văn phòng của mình mà không cần card đồ họa rời đắt tiền? Với sự hỗ trợ của Intel IPEX-LLM, việc tận dụng sức mạnh của iGPU (card đồ họa tích hợp) để chạy AI local đã trở nên đơn giản hơn bao giờ hết.
Điều kiện tiên quyết
Để bắt đầu, máy tính của bạn cần trang bị phần cứng Intel tương thích đã được xác thực:
- CPU: Intel Core Ultra hoặc Intel Core thế hệ 11 đến 14.
- GPU: Intel Arc A-Series, Arc B-Series hoặc Iris Xe Graphics.
- Hệ điều hành: Windows 10/11 (khuyên dùng bản 22H2 trở lên).
Cập nhật Driver đồ họa
Đây là bước bắt buộc. Bạn cần cài đặt phiên bản driver 32.0.x trở lên để IPEX-LLM có thể hoạt động ổn định.
Chọn phiên bản phù hợp (Ở đây máy mình sử dụng Intel Core i5-1235U):

Lưu ý: Các bạn cũng có thể sử dụng Intel Driver & Support Assistant ở bên trái để tự tìm phiên bản phù hợp
Windows sẽ xóa driver cũ và cài đặt phiên bản mới nhất (32.0.x)
Sau khi cài đặt và cập nhật Driver lên phiên bản mới nhất (Kiểm tra trên phần mềm Intel Graphics Software)
Tải Ollama Portable (IPEX-LLM)
Thay vì cài đặt bản Ollama thông thường, bạn cần tải bản Ollama portable zip dành riêng cho Windows có tích hợp IPEX-LLM (ví dụ: ollama-ipex-llm-2.3.0b...win.zip).
Lưu ý: Đây là bản pre-build Portable chạy sẵn (tức là chỉ cần tải và chạy). Nếu bạn muốn tự build bản mới nhất thì có thể tham khảo hướng dẫn của Intel/IPEX-LLM
Thiết lập dịch vụ Ollama
Giải nén: Giải nén file zip vừa tải vào một thư mục (ví dụ: D:\Program\ollama-ipex-llm).
Mở CMD và di chuyển đến folder cài đặt.
Khởi động dịch vụ: Chạy file start-ollama.bat (có thể thêm vào Windows Services để chạy tự động)
Một cửa sổ CMD sẽ hiện ra, thông báo dịch vụ Ollama đang chạy và sẵn sàng nhận lệnh.
Kiểm tra phiên bản: Phiên bản Ollama Portable hiện tại đang là 0.9.3
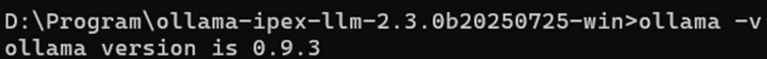
Pull model Ollama để sử dụng (bạn có thể sử dụng bất kỳ model nào khác)
ollama pull deepseek-r1:7bỞ cửa sổ ollama serve cho thấy card GPU đang được nhận diện đúng (ví dụ: Intel Iris Xe Graphics với 12GB VRAM chia sẻ).

Chạy Ollama model với GPU
Chạy model với chế độ debug để kiểm tra hiệu năng
ollama run deepseek-r1:7b --verboseKiểm tra Performance cho thấy đang sử dụng GPU thay vì CPU
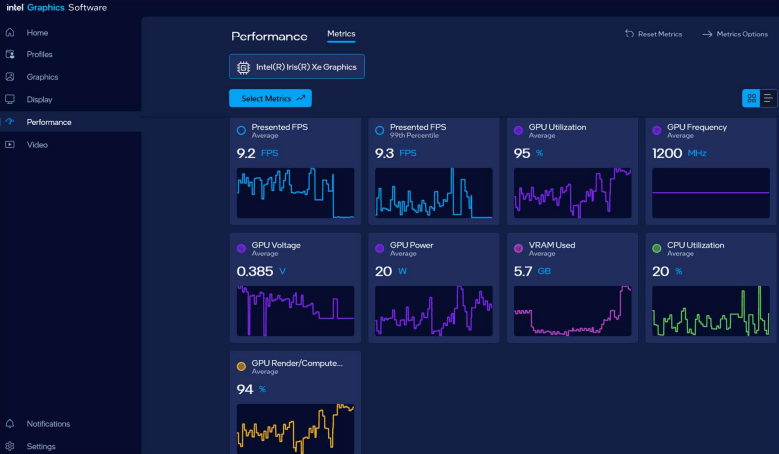
Sau khi hoàn thành ta sẽ thấy thông số khi chạy rơi vào 6.5 tokens/s
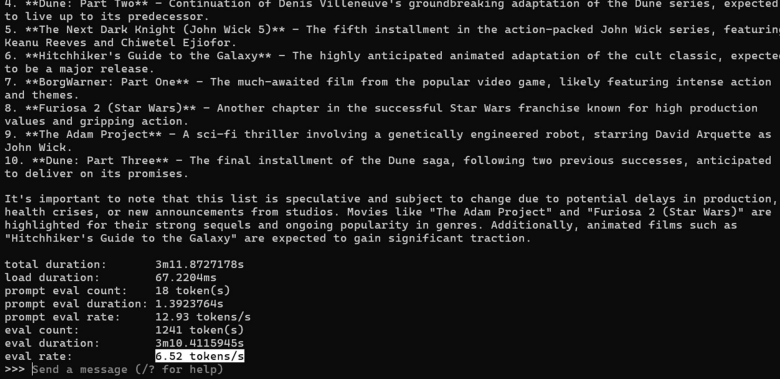
Lưu ý: Con số này sẽ thay đổi dựa vào khả năng xử lý của mỗi máy và model khác nhau (thực tế có thể khác so với máy của bạn)
Tùy chỉnh nâng cao
Bạn có thể chỉnh sửa file ollama-serve.bat để tối ưu hóa hoặc thay đổi cách thức hoạt động của hệ thống bằng các biến môi trường:
set OLLAMA_NUM_GPU=999: Ép buộc sử dụng GPU.set OLLAMA_NUM_GPU=0: Chuyển hoàn toàn sang chạy bằng CPU (nếu muốn).set ZES_ENABLE_SYSMAN=1: Bật quản lý hệ thống để tối ưu hiệu năng Intel.
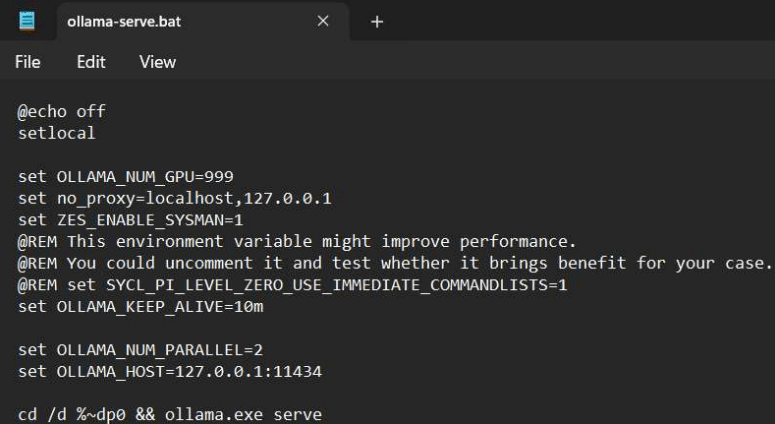
Ví dụ sửa OLLAMA_NUM_GPU=0 để chạy bằng CPU. Lúc này Ollama sẽ sử dụng CPU và GPU hoàn toàn không được sử dụng.
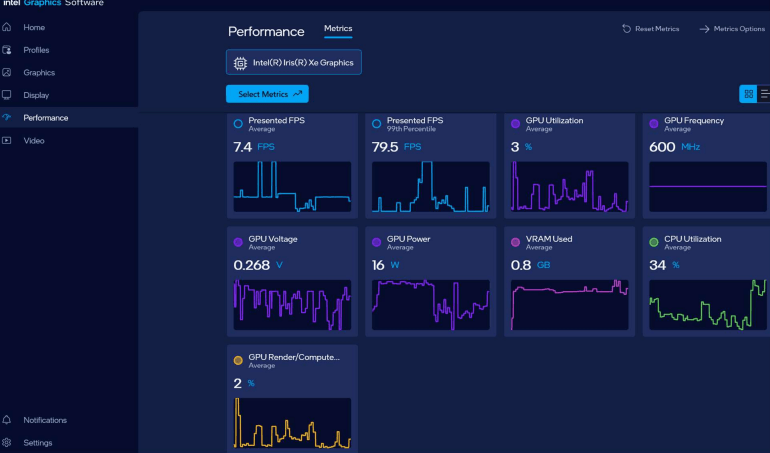
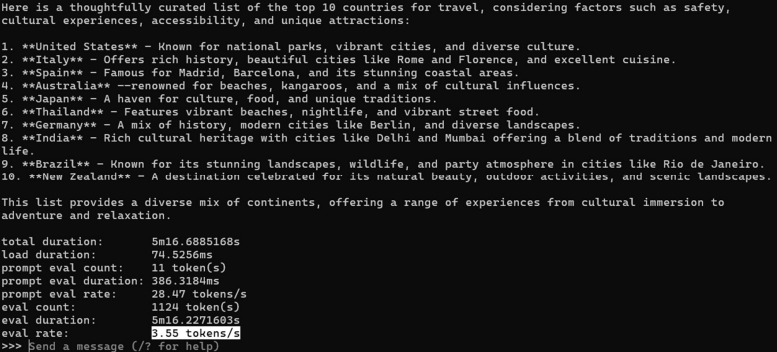
Kiểm tra kết quả thì hiệu suất rơi vào 3.5 tokens/s (khoảng 60%)
So sánh hiệu năng iGPU và CPU
Một thử nghiệm thực tế với mô hình DeepSeek-R1:7b trên chip Intel Core i5-1235U cho thấy sự khác biệt rõ rệt:
| Thông số | Chạy bằng iGPU (IPEX-LLM) | Chạy bằng CPU (mặc định) |
| Tốc độ phản hồi (eval rate) | 6.52 tokens/s | 3.55 tokens/s |
| Mức độ sử dụng GPU | ~95% | ~3% |
| Hiệu suất so sánh | 100% | ~60% |
Việc sử dụng iGPU giúp tốc độ xử lý nhanh gần gấp đôi so với chỉ dùng CPU, mang lại trải nghiệm mượt mà hơn khi chat với AI.
Benchmark từ trang chủ thì tokens khi chạy bằng iGPU của Intel sẽ vào khoảng 6-8 tokens/s
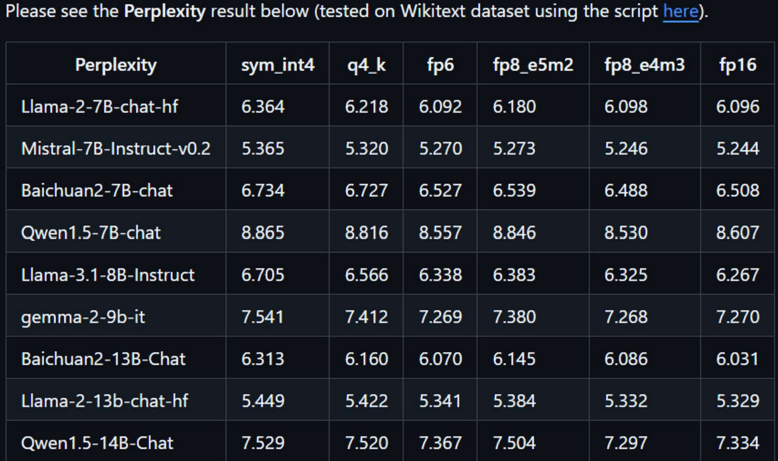
Kết luận
Nhờ IPEX-LLM, những chiếc laptop văn phòng trang bị chip Intel đời mới giờ đây đã có thể trở thành một “trạm AI” mini đầy mạnh mẽ. Hãy cập nhật ngay driver mới nhất và trải nghiệm tốc độ AI local ngay hôm nay!