


Lời nói đầu
Mặc dù Prometheus 2.0 đã được ra mắt từ 2015, nhưng không có nhiều tài nguyên để hiểu về TSDB ngoại trừ bài đăng trên blog của Fabian , đây là bài đăng ở cấp độ rất cao, và tài liệu về định dạng giống như tài liệu tham khảo dành cho nhà phát triển hơn.
Gần đây, TSDB của Prometheus đã thu hút rất nhiều cộng tác viên mới, và việc thiếu hụt nguồn lực là một trong những khó khăn. Vì vậy, tôi dự định sẽ thảo luận chi tiết về cách thức hoạt động của TSDB trong một loạt bài đăng trên blog cùng với một số tài liệu tham khảo về mã nguồn dành cho cộng tác viên.
Trong bài này, tôi chủ yếu nói về phần in-memory của TSDB – Head block – trong khi tôi sẽ đi sâu hơn vào các thành phần khác như WAL và checkpoint, cách thiết kế memory-mapping của chunks, compaction, persistent blocks và index, cũng như snapshot các chunks.
Bài viết trên blog của Fabian rất đáng đọc để hiểu về mô hình dữ liệu, các khái niệm cốt lõi và bức tranh tổng quan về cách thiết kế TSDB. Anh ấy cũng đã có bài phát biểu tại PromCon 2017 về chủ đề này. Tôi khuyên bạn nên tham khảo blog hoặc xem bài phát biểu trước khi tìm hiểu sâu hơn về chủ đề này để có nền tảng vững chắc.
Tổng quan về TSDB
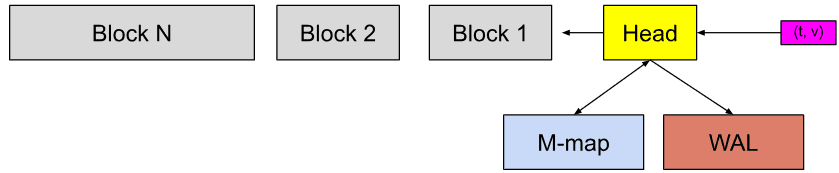
Trong hình trên, Head block là phần in-memory của cơ sở dữ liệu và các khối màu xám là persistent blocks trong disk, không thể thay đổi. Chúng ta có Write-Ahead-Log (WAL) cho các thao tác ghi bền vững. Một incoming sample (ô màu hồng) trước tiên sẽ đi vào Head block và lưu lại trong memory một thời gian, sau đó được flush vào disk và memory-mapped (ô màu xanh).
Khi các memory mapped chunks hoặc in-memory chunks trở nên cũ đến một mức độ nhất định, chúng sẽ được flush vào disk dưới dạng các persistent blocks. Tiếp theo, nhiều khối được hợp nhất khi chúng cũ đi và cuối cùng bị xóa sau khi vượt quá thời gian lưu giữ.
Vòng đời Sample trong Head block
Mọi cuộc thảo luận ở đây đều nói về một time series duy nhất và điều này cũng đúng với tất cả các chuỗi.
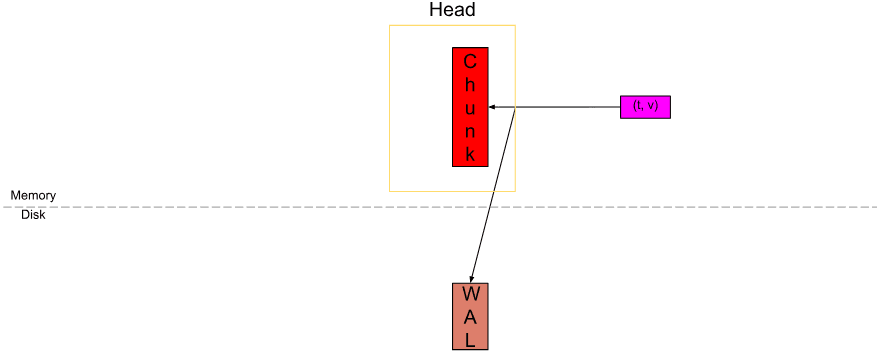
Samples được lưu trữ trong các đơn vị nén gọi là “chunk”. Khi một sample được gửi đến, nó sẽ được đưa vào “active chunk” (khối màu đỏ). Đây là đơn vị duy nhất mà chúng ta có thể chủ động ghi dữ liệu.
Khi đưa sample vào chunk, chúng tôi cũng ghi lại nó vào Write-Ahead-Log (WAL) trên disk (khối màu nâu) để đảm bảo độ bền (có nghĩa là có thể khôi phục dữ liệu in-memory từ đó ngay cả khi bị sập đột ngột).

Khi chunk đầy đến 120 samples (hoặc) trải dài đến phạm vi chunk/block (tạm gọi là chunkRange), tức là 2 giờ theo mặc định, một chunk mới sẽ được cắt và chunk cũ được coi là “đầy”. Trong bài này, chúng ta sẽ coi scape interval là 15 giây, vì vậy 120 samples (một full chunk) sẽ trải dài 30 phút.
Khối màu vàng có số 1 là chunk hoàn chỉnh vừa được điền đầy trong khi khối màu đỏ là chunk mới được tạo ra.
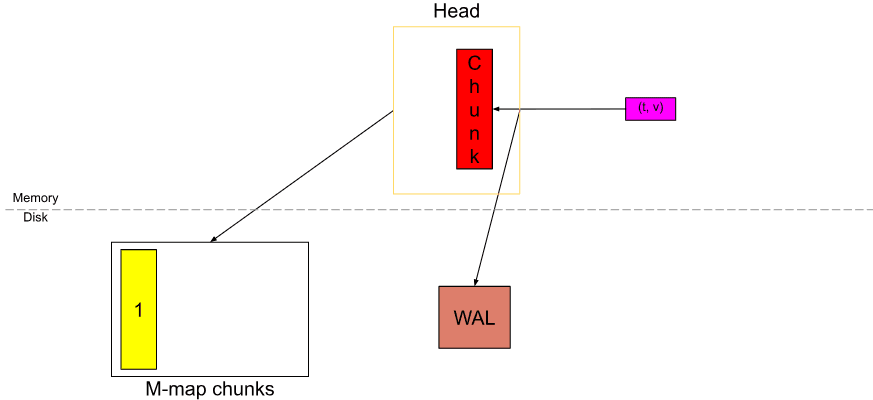
Kể từ Prometheus v2.19.0, chúng ta không lưu trữ tất cả các chunks trong bộ nhớ. Ngay khi một chunk mới được cắt, toàn bộ full chunk sẽ được flush vào disk và memory-mapped từ disk, đồng thời chỉ lưu trữ một tham chiếu trong bộ nhớ. Với memory-mapping, chúng ta có thể tải chunk vào bộ nhớ với tham chiếu đó một cách động khi cần; đây là một tính năng được cung cấp bởi Hệ điều hành.
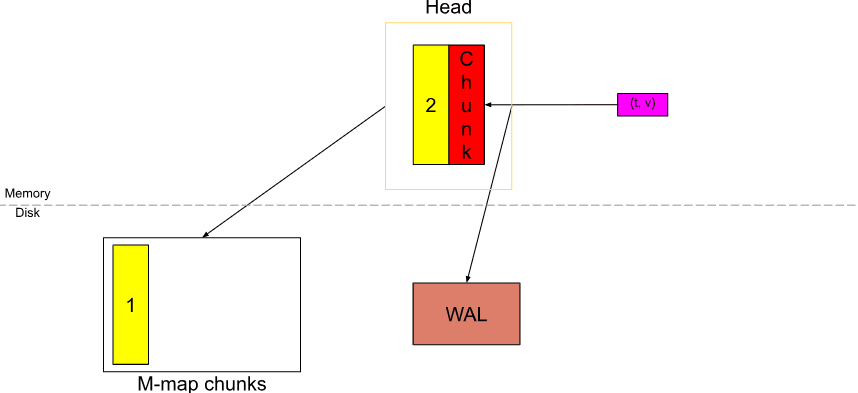
Tương tự như vậy, khi các samples mới liên tục xuất hiện, các chunks mới sẽ được cắt ra.
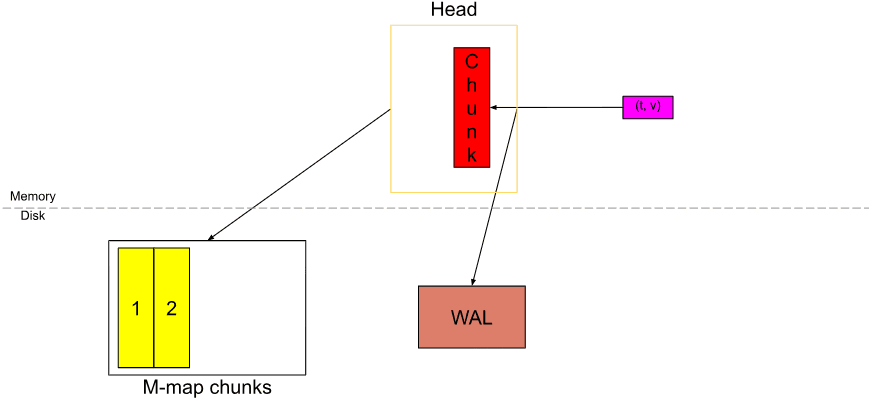
Và chúng được flush vào disk và memory-mapped.
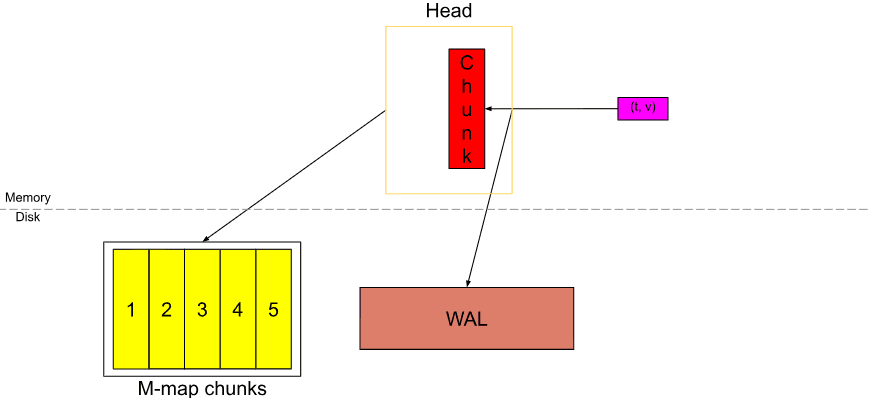
Sau một thời gian, Head block sẽ trông như trên. Nếu chúng ta coi chunk màu đỏ gần đầy, thì chúng ta có 3 giờ dữ liệu trong Head (6 chunks, mỗi khối dài 30m). Tức là chunkRange*3/2.
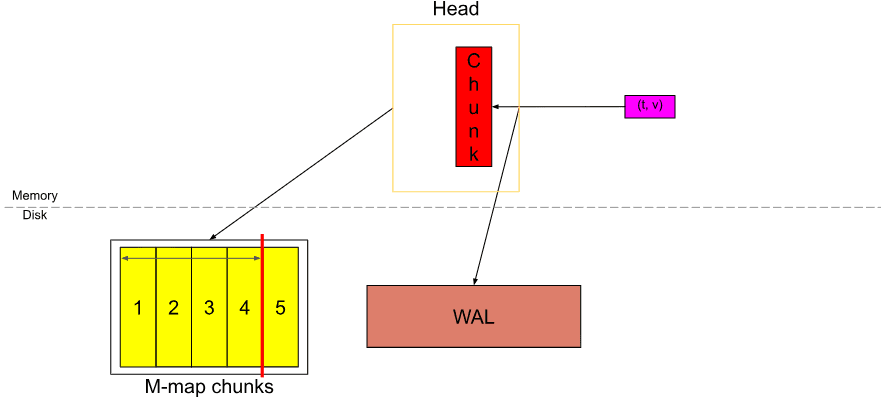
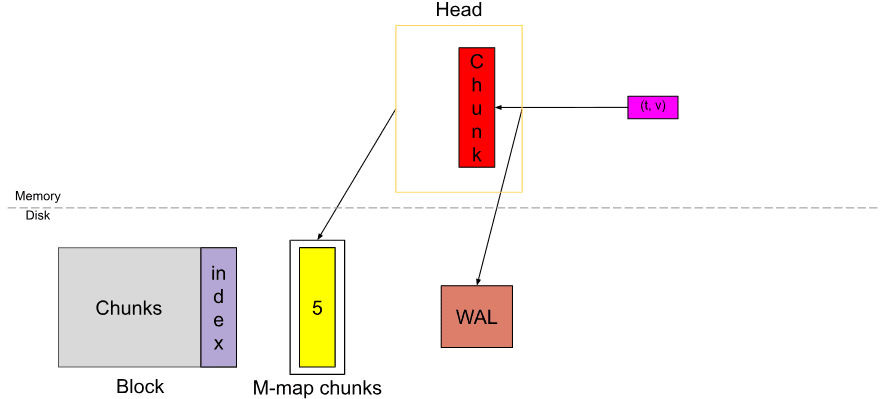
Khi dữ liệu trong Head trải dài chunkRange*3/2, dữ liệu chunkRange đầu tiên (2h ở đây) được nén thành persistent block. Nếu bạn thấy ở trên, WAL bị cắt ngắn tại thời điểm này và một “checkpoint” được tạo ra (không hiển thị trong sơ đồ).
Chu trình thu thập samples, memory-mapping, nén để tạo thành một persistent block này cứ tiếp diễn. Và đây chính là chức năng cơ bản của Head block.
Một số điều cần lưu ý
Index ở đâu
Nó nằm trong bộ nhớ và được lưu trữ dưới dạng index đảo ngược. Tìm hiểu thêm về ý tưởng tổng thể của chỉ mục này trong bài đăng trên blog của Fabian. Khi quá trình nén Head block diễn ra, tạo ra một persistent block, Head block sẽ bị cắt bớt để loại bỏ các chunks cũ và quá trình thu gom rác được thực hiện trên index này để loại bỏ bất kỳ series entries nào không còn tồn tại trong Head.
Xử lý Khởi động lại
Trong trường hợp TSDB phải khởi động lại (bình thường hoặc đột ngột), nó sẽ sử dụng on-disk memory-mapped chunks và WAL để phát lại dữ liệu và sự kiện, đồng thời xây dựng lại in-memory index và chunk.
Code tham khảo
tsdb/db.go điều phối hoạt động chung của TSDB.
Đối với các phần có liên quan trong bài đăng trên blog, logic cốt lõi của quá trình thu thập dữ liệu cho các khối trong bộ nhớ đều nằm ở tsdb/head.go việc sử dụng WAL và memory mapping như black box.