


Giới thiệu
Machine Learning (ML) – Học máy là 1 trong số những khái niệm đầu tiên mà bất kỳ ai khi tìm hiểu/học về AI sẽ đều phải làm quen và nắm được. Các bạn nếu gõ từ khóa Definition of Machine Learning hay What is Machine Learning? lên Google thì sẽ thấy có vô số định nghĩa/giải thích, từ thông dụng, gần gũi cho đến hàn lâm, học thuật.
Tuy nhiên hôm nay mình sẽ giúp các bạn làm quen với khái niệm này theo 1 cách tiếp cận khác, rất dễ hiểu, bằng việc đưa ra sự tương đồng giữa cách máy học với cách con người học, từ đó giúp các bạn có thể hiểu 1 cách chính xác về Machine Learning – thuật ngữ cơ bản và quan trọng bậc nhất trong lĩnh vực AI
Về bản chất, ML là nơi mà chúng ta mô phỏng cách thức con người học tập lên các mô hình, hay nói cách khác, con người được đào tạo như thế nào thì các mô hình cũng được đào tạo tương tự vậy
So sánh để hình dung
Hãy làm phép so sánh 1-1 để thấy sự tương đồng này:
Trong thế giới của con người, đối tượng được đào tạo là học sinh. Còn trong ML, đối tượng được đào tạo là các mô hình. Trong ML thì thường người ta không gọi là đào tạo mô hình, mà sẽ gọi là huấn luyện mô hình. Do đó thì từ giờ cho đến cuối bài viết mình sẽ dùng từ này.

Hàng ngày, học sinh sẽ học thông qua việc làm bài tập (e.g. các bạn lớp 1 học toán thì hàng ngày sẽ làm bài tập về cộng trừ trong phạm vi 100, lớp 2 học toán thì hàng ngày làm bài tập về bảng cửu chương, lớp 12 học toán thì hàng ngày các bạn học sinh sẽ làm các bài tập về khảo sát hàm số, đạo hàm, tích phân, lượng giác,…). Điều này giống như việc chúng ta đưa dữ liệu vào mô hình trong ML. Hay nói cách khác, chúng ta tiếp nhận bài tập = mô hình tiếp nhận dữ liệu.
Quy tắc chung áp dụng cả trong thế giới của con người cũng như trong ML: Muốn con người/mô hình làm được cái gì thì phải đưa vào bài tập/dữ liệu về đúng thứ đó. Muốn các bạn học sinh biết cách tính đạo hàm thì phải đưa cho học sinh các bài toán về đạo hàm. Muốn mô hình dự đoán được giá của các căn nhà thì phải đưa vào mô hình thông tin liên quan (e.g. diện tích, số tầng, số phòng, vị trí, …) của những căn nhà đó.
Sau khi nhận bài tập, học sinh sẽ suy nghĩ, làm bài và đưa ra bài làm của mình. Tương tự như vậy, sau khi nhận dữ liệu đầu vào, mô hình sẽ tương tác với dữ liệu. Tương tác như thế nào thì còn tùy thuật toán cụ thể của mỗi mô hình, cũng giống như với cùng 1 bài toán thì mỗi học sinh sẽ có 1 cách tiếp cận khác nhau. Kết quả của sự tương tác này là dự đoán của mô hình cho dữ liệu đầu vào đó (e.g. giá của căn nhà, tương ứng với thông tin về diện tích, số tầng, số phòng, vị trí,… mà ta đưa vào)
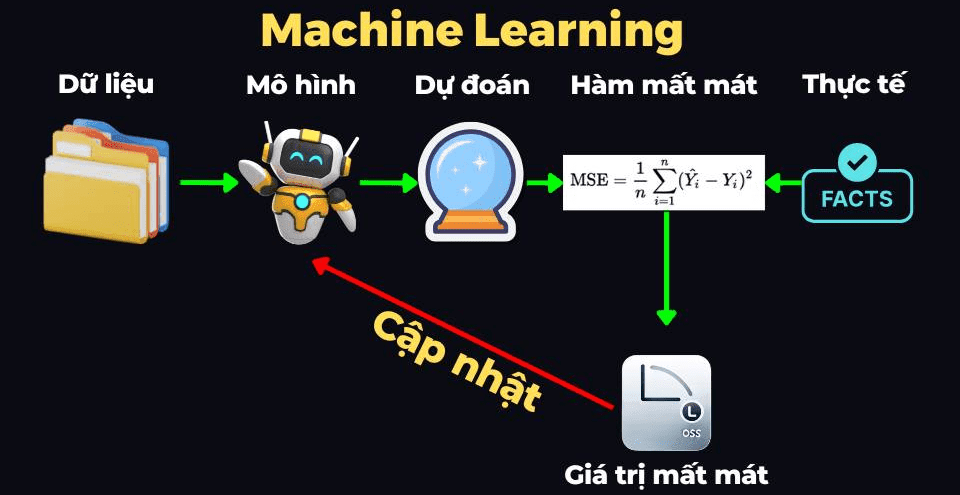
Bài làm của học sinh có thể đúng, có thể sai. Nếu sai thì có thể sai ít, sai nhiều. Tương tự như vậy, dự đoán của mô hình cũng có thể đúng, có thể sai, sai cũng có thể sai ít hoặc sai nhiều. Để đánh giá được khả năng của học sinh, thông qua bài làm của học sinh đó, chúng ta cần có giáo viên. Để đánh giá được chất lượng của mô hình, thông qua dự đoán của mô hình đó, chúng ta có 1 thứ, được gọi là hàm mất mát (loss function).
Giáo viên sẽ không thể tay không chấm bài, mà sẽ cần có đáp án có sẵn, để có thể đối chiếu với bài làm của học sinh. Tương tự như vậy, hàm mất mát cũng cần có giá trị thực sự của căn nhà (trong AI/ML người ta gọi là ground-truth) để so sánh giá trị này với giá trị dự đoán mà mô hình đưa ra.
Khi chấm bài cho học sinh, giáo viên sẽ chỉ ra chỗ nào học sinh làm đúng, chỗ nào học sinh làm sai. Bài làm của học sinh càng ít lỗi thì càng tốt. Tương tự như vậy, hàm mất mát sẽ đánh giá sự sai lệch giữa giá trị dự đoán của mô hình và giá trị thực tế, 2 giá trị này càng lệch nhau ít thì giá trị mất mát (loss value) càng bé => mô hình càng tốt.
Sau khi giáo viên chấm xong bài, giáo viên sẽ trả lại bài chữa cho học sinh. Học sinh sẽ dựa vào bài chữa này để cải thiện bản thân, để lần sau làm bài sẽ tốt hơn. Tương tự như vậy, hàm mất mát sẽ tính và trả về giá trị mất mát, và mô hình sẽ được cập nhật và cải thiện dựa vào giá trị mất mát này. Dựa vào bằng cách nào thì mình sẽ nói chi tiết hơn ở 1 bài viết khác.
Trong thực tế, ít khi học sinh làm 1 bài tập đơn lẻ, mà thường là sẽ làm nhiều bài tập 1 lúc (e.g. 10, 20 bài,…), rồi nộp để giáo viên chấm 1 thể. Tương tự như vậy, trong quá trình huấn luyện mô hình, mỗi lần đưa dữ liệu vào mô hình, người ta ít khi đưa lẻ thông tin của 1 căn nhà vào mô hình, mà thường sẽ đưa cả 1 cụm dữ liệu của nhiều căn nhà vào 1 lúc để mô hình dự đoán 1 thể. Một cụm dữ liệu như vậy trong ML người ta gọi là 1 minibatch.
Quá trình trên sẽ lặp đi lặp lại nhiều lần. Bài tập -> học sinh làm bài -> bài làm -> giáo viên chấm -> học sinh cải thiện bản thân. Tương tự: Dữ liệu đầu vào -> mô hình tương tác với dữ liệu -> đưa ra dự đoán -> hàm mất mát so sánh dự đoán với thực tế để tính ra giá trị mất mát -> mô hình được cập nhật.
Ngưỡng đạt được trong học máy
Có 1 điều mà mình thấy ít tài liệu về AI/ML nói đến. Trong thế giới của chúng ta, chúng ta học với mục đích là làm cho bản thân ngày càng giỏi hơn, tốt hơn. Tuy nhiên điều đó không có nghĩa là chúng ta học càng nhiều thì chúng ta sẽ càng giỏi.
Trong quá trình học, đến 1 lúc nào đó chúng ta sẽ đạt đến ngưỡng của bản thân. Tức là sau đó, dù cố gắng học nữa thì chúng ta cũng không thể giỏi lên được. Ví dụ, các bạn học sinh học đến 1 mức nào đó sẽ được tầm 9 điểm môn toán, và sau đó các bạn có học thêm nữa thì điểm của các bạn cũng không tăng thêm được. Hay với các bạn đang học TOEIC, các bạn học đến 1 lúc nào đó sẽ được tầm 800 điểm, và sau đó nếu các bạn có cố học thêm nữa thì điểm của các bạn cũng không tăng lên được.
Điều này cũng đúng trong ML. Chúng ta huấn luyện mô hình với mong muốn là mô hình sẽ ngày càng tốt hơn, dự đoán càng chính xác hơn. tuy nhiên, đến 1 lúc nào đấy, mô hình sẽ chạm ngưỡng của nó. Đó là khi giá trị mất mát không tiếp tục giảm nữa. Lúc này thì dù có tiếp tục huấn luyện mô hình thì mô hình cũng không thể được cải thiện thêm nữa.
Trong thế giới của con người, bài tập là rất quan trọng trong quá trình dạy học 1 học sinh. Bài tập chất lượng, có liên quan đến vấn đề mà ta muốn dạy học sinh, và phù hợp với khả năng của học sinh thì học sinh mới học tốt được. Tương tự như vậy, trong ML, dữ liệu là vô cùng quan trọng trong quá trình huấn luyện mô hình. Dữ liệu tốt, và có liên quan đến vấn đề cần giải quyết, và phù hợp với khả năng của mô hình thì mô hình mới có thể được cải thiện.
Nếu chúng ta đưa cho học sinh lớp 12 bài toán của sinh viên đại học, thì chắc chắn học sinh sẽ không thể nào làm bài tốt được, và học sinh sẽ không cải thiện được trình độ khi làm những bài tập có độ khó vượt trình độ của bản thân như thế này. Tương tự như vậy, nếu độ phức tạp của dữ liệu lớn hơn so với độ phức tạp của mô hình, thì mô hình sẽ không học hỏi được gì từ dữ liệu. Hiện tượng này trong ML được gọi là underfitting. Ngược lại chúng ta có hiện tượng overfitting, khi độ phức tạp của mô hình lớn hơn độ phức tạp của dữ liệu.
Lời kết
Thật ra, trong Machine Learning, có rất nhiều các mô hình khác nhau, và toàn bộ những gì mình viết ở trên chỉ đúng với 1 họ các mô hình phổ biến và có nhiều ứng dụng nhất trong Machine Learning, đó là các mô hình học có giám sát. Với các mô hình khác thì sẽ có 1 vài bước ở trên cần phải có 1 chút thay đổi. Tuy nhiên khi mới học AI/ML cũng như sau này khi đi làm, các mô hình học có giám sát sẽ là những đối tượng mà chúng ta dành phần lớn thời gian để học và sử dụng.
Mình hy vọng những chia sẻ của mình trong bài viết này hữu ích với các bạn, đặc biệt là các bạn đang bắt đầu tìm hiểu về AI/ML.